Background
What is metadata?
Metadata means data about data. While providing a summary of data, metadata does not provide the content of data itself. Another way to think about metadata is as a library catalogue: it has information about what is available in the library, but doesn’t include any of the information contained in the books. Like a library catalogue, having access to metadata doesn’t mean you have access to the data, but it allows you to see what’s available and what types of things you might be interested in improving or exploring. Metadata helps the classification, access, and storage of data.

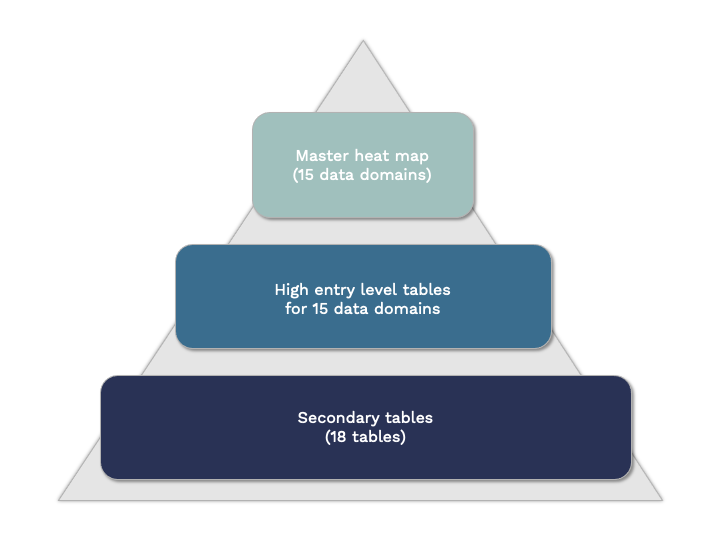
 Led by postdoctoral fellow Dr. Adriana Rodriguez Cruz, the CTN Metadata Project team collected the protocols and documentation from 12 cohort studies. The team then extracted all of the metadata from these documents to create a standardized list of variables collected across these studies. The variables were grouped by subject area and other more specific characteristics and placed into a series of tables, ranging from a general overview to granular details about specific types of data and how they were collected.
Led by postdoctoral fellow Dr. Adriana Rodriguez Cruz, the CTN Metadata Project team collected the protocols and documentation from 12 cohort studies. The team then extracted all of the metadata from these documents to create a standardized list of variables collected across these studies. The variables were grouped by subject area and other more specific characteristics and placed into a series of tables, ranging from a general overview to granular details about specific types of data and how they were collected.